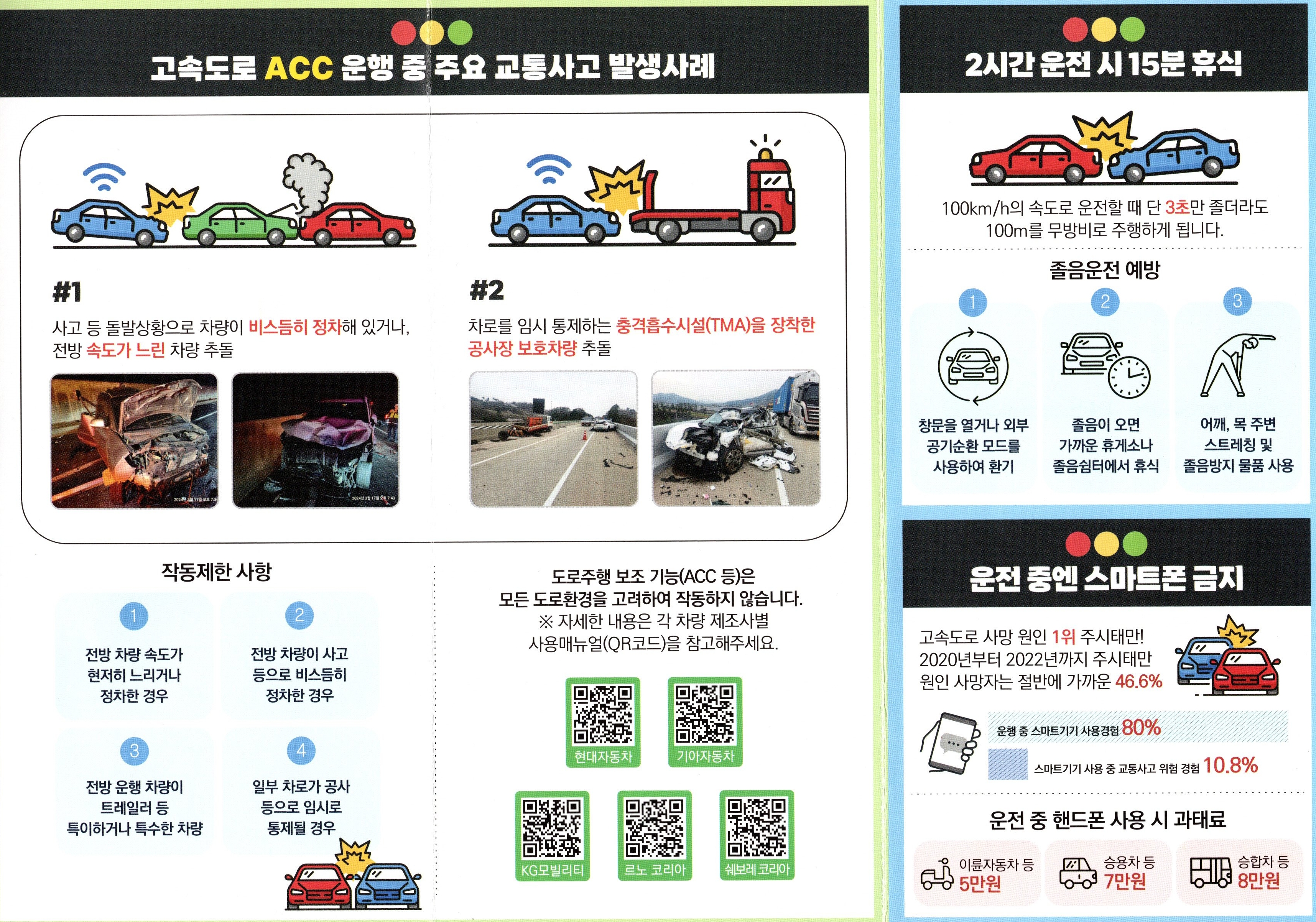
은행(예를 들어, 위 이미지는 IBK기업은행)에서 해외로 송금할 때,
발생하는 비용은 크게 송금수수료, 전신료, 대체료, 중개수수료 등으로 나뉩니다.
- 송금수수료: Remittance Fee (또는 Outward Remittance Fee)
- 전신료: Cable Charge (또는 Telegraphic Transfer Charge, 줄여서 T/T Charge)
- 중개수수료: Intermediary Fee (또는 Correspondent Bank Fee)
- 대체료: In lieu of Exchange Commission
특히 대체료의 영어 표현이 독특한데, 직역하면 "환전(Exchange)을 대신(In lieu of)해서 받는 수수료"라는 뜻입니다.
* in lieu of = … 대신에(instead of)
- Remittance Fee: 은행이 송금 업무 대행 서비스 자체에 대해 받는 수수료입니다.
- Cable Charge: 해외 은행과 통신(SWIFT망 등)을 주고받는 데 발생하는 실비 성격의 비용입니다.
- Intermediary Fee: 송금 경로 중간에 있는 중개은행이 떼어가는 수수료입니다.
- In lieu of Exchange Commission: 고객이 이미 가지고 있는 외화(현찰 또는 외화계좌 잔액)를 사용하여 송금할 때, 은행이 환전 수익을 얻지 못하는 대신 청구하는 수수료입니다.
[참고] 해외에서 한국으로 돈을 받을 때는 '송금수수료' 대신 Inward Remittance Fee (추심수수료/입금수수료)라는 용어를 사용합니다.
▶ 송금수수료 계산 방식 (금액별)
송금수수료는 보내시는 미화(USD) 환산 금액을 기준으로 다음과 같이 부과됩니다. (창구 기준)
| 송금 금액 (USD 기준) | 영업점 창구 이용 시 | 모바일/인터넷 뱅킹 이용 시 |
| $500 이하 | 5,000원 | 면제 (또는 2,500원) |
| $500 초과 ~ $2,000 이하 | 10,000원 | 면제 (또는 5,000원) |
| $2,000 초과 ~ $5,000 이하 | 15,000원 | 면제 (또는 7,500원) |
| $5,000 초과 ~ $20,000 이하 | 20,000원 | 면제 (또는 10,000원) |
| $20,000 초과 | 25,000원 | 면제 (또는 10,000원) |
핵심 팁: 기업은행은 비대면(i-ONE 뱅크 등)으로 원화계좌에서 출금하여 송금할 경우 송금수수료를 면제해주는 혜택을 자주 제공합니다. 반면, 외화계좌에서 바로 보내거나 영업점을 방문하면 위 표와 같은 수수료가 발생합니다.
▶ 전신료 (Cable Charge)
전신료는 금액과 상관없이 발생하는 고정 비용 성격이 강합니다.
- 영업점 창구: 8,000원
- 비대면(인터넷/모바일): 5,000원
▶ 주의사항: 중개수수료 (Intermediary Fee)
송금수수료와 전신료 외에 중개은행 수수료라는 것이 추가로 발생할 수 있습니다.
- 돈이 해외 은행에 도착하기까지 거쳐가는 중간 은행들이 떼어가는 비용입니다. (보통 $15~$25 내외)
- 송금인 부담(OUR): 보낼 때 미리 지불 (약 2~3만 원 추가)
- 수취인 부담(SHA): 받는 금액에서 차감 (받는 사람이 적게 받음)
💡 요약하자면
가장 저렴하게 보내시려면 i-ONE 뱅크 앱을 이용해 원화계좌에서 바로 송금하세요. 이 경우 송금수수료 면제 + 전신료 5,000원만으로 처리가 가능하며, 환율 우대 혜택도 동시에 받으실 수 있습니다.
중개수수료 (Intermediary Fee) / OUR vs. BEN·SHA
중개수수료는 결론부터 말씀드리면, 송금액에 비례해서 늘어나는 방식이 아니라 '건당 정액'으로 부과되는 것이 일반적입니다.
하지만 금액이 아주 커지면 상황이 조금 달라질 수 있으니, 아래의 상세 내용을 확인해 보세요.
1. 기본은 '건당 정액' ($15 ~ $25)
중개은행은 송금액이 100만 원이든 1,000만 원이든, 시스템을 거쳐 가는 **'한 건의 작업'**에 대해 수수료를 받습니다.
- 보통 미화 기준으로 $15 ~ $25 사이에서 결정됩니다.
- 송금하는 국가나 중개하는 은행(씨티, JP모건 등)의 정책에 따라 조금씩 차이가 날 뿐, 송금액이 많다고 해서 중개수수료가 $100, $200식으로 계속 올라가지는 않습니다.
2. 금액이 클 때 발생하는 차이 (Post-Charging)
다만, 송금액이 수만 달러(약 5,000만 원 이상) 단위로 매우 커지는 경우에는 중개은행에서 정액이 아닌 **금액의 일정 비율(예: 0.05% ~ 0.1%)**을 차감하는 경우도 드물게 발생합니다.
- 하지만 일반적인 개인 송금 규모에서는 대부분 **정액($18~$20 수준)**으로 처리된다고 보셔도 무방합니다.
3. 누가 내느냐의 차이 (송금 시 선택)
중개수수료는 계산 방식보다 **'누가 부담하느냐'**가 더 중요합니다.
| 선택 옵션 | 설명 | 특징 |
| 송금인 부담 (OUR) | 보낼 때 중개수수료를 미리 지불 | 받는 사람이 송금액 전액을 그대로 받음 (유학비, 물품 대금 등 추천) |
| 수혜자(수취인) 부담 (BEN, Beneficiary) |
받는 사람이 모든 수수료를 지불 | 국내 수수료까지 포함한 모든 비용을 송금액 원금에서 빼고 보냄. 보내는 사람은 당장 내는 돈이 없지만, 받는 금액이 많이 줄어듦. |
| 공동부담 부담 (SHA, Shared) |
수수료 분담 | 보내는 사람은 국내 수수료, 받는 사람은 해외 수수료 지불 |
* 'SHA': 송금 과정에서 발생하는 수수료를 송금인과 수취인이 '나누어 부담한다'는 의미. 이 옵션을 선택하면 송금인(보내는 사람)은 국내 은행(IBK기업은행)에 지불하는 송금수수료와 전신료를 부담하고, 수취인(받는 사람)은 현지 은행에 도착하기 전까지 발생하는 중개수수료와 현지 수취수수료를 부담합니다. (이 비용은 송금액 원금에서 차감되고 남은 금액만 통장에 입금됩니다.)
💡 팁: IBK기업은행을 쓰신다면?
기업은행의 'i-ONE 뱅크' 앱에서 송금할 때 '[수수료 송금인 부담]'을 선택하면, 아예 중개수수료까지 포함된 확정 금액을 원화로 결제할 수 있습니다. 나중에 수취인이 "돈이 2만 원 비게 왔다"라고 하는 상황을 방지하고 싶다면 이 옵션을 추천드려요.
대체료 (In lieu of Exchange Commission)
'대체료'는 쉽게 말해 "은행이 현금(종이돈) 없이 숫자만 움직여줄 때 발생하는 비용"이라고 이해하시면 됩니다.
전문적으로는 현찰 수수료와 상충하는 개념인데, 상황별로 왜 발생하는지 핵심만 짚어드릴게요.
1. 대체료가 발생하는 이유
은행 입장에서 해외송금을 보낼 때, 고객이 가져온 돈이 '어떤 상태'냐에 따라 수수료가 달라집니다.
- 원화 계좌에서 출금해서 보낼 때: 은행은 원화를 받아서 달러로 환전해 보내야 합니다. 이때는 환전 이익이 발생하므로 보통 대체료를 받지 않습니다.
- 외화 계좌에 있던 달러를 보낼 때: 이미 내 계좌에 들어있는 달러를 보내는데도 은행은 '대체료'를 요구할 때가 있습니다. "내 돈 내가 보내는데 왜?"라고 느끼실 수 있지만, 은행 입장에서는 외화 현찰을 관리하거나 시스템상 숫자를 이동시키는 비용을 청구하는 것입니다.
2. 언제, 얼마나 내나요?
기업은행을 포함한 대부분의 시중은행에서 다음과 같은 경우에 발생합니다.
- 발생 상황: 외화 계좌에 보관 중인 외화를 그대로 해외로 송금할 때 주로 발생합니다.
- 금액: 보통 송금액의 0.1% 정도가 부과됩니다.
- 예: $10,000 송금 시 약 $10 내외 (최저/최고 한도가 정해져 있는 경우가 많습니다.)
3. 대체료를 안 내는 방법 (꿀팁)
대체료는 보통 **'외화 현찰'**과 관련이 깊습니다. 만약 외화 계좌에 돈을 넣은 지 7일~10일이 지났거나, 애초에 원화를 입금해서 바로 달러로 바꿔 보내는 '전신환' 형태의 송금이라면 대체료가 면제되는 경우가 많습니다.
💡 정리하자면
대체료는 외화 계좌에 있는 돈을 꺼내어 해외로 쏠 때 발생하는 '숫자 이동 비용'입니다.
만약 원화 통장에서 바로 돈을 빼서 해외로 보내시는 상황이라면, 대체료 걱정은 크게 안 하셔도 됩니다. (보통 송금수수료와 전신료만 발생합니다.)